[이전 글 보기]
2020/03/22 - [AI/자연어처리] - [생활속의 IT] 자연어 처리#1 - 아나콘다 설치하기
2020/03/22 - [AI/자연어처리] - [생활속의 IT] 자연어 처리 - 참고) Jupyter의 개념
2020/03/23 - [AI/자연어처리] - [생활속의 IT] 자연어 처리#2 - 크롤러 만들기
2020/03/23 - [AI/자연어처리] - [생활속의 IT] 자연어 처리#3 - 직방의 지리정보 Geohash 이해하기
2020/03/24 - [AI/자연어처리] - [생활속의 IT] 자연어 처리#4 - 직방 아파트ID 얻기
2020/03/24 - [AI/자연어처리] - [생활속의 IT] 자연어 처리#5 - 직방 부동산 평가 크롤링하기
2020/03/26 - [AI/자연어처리] - [생활속의 IT] 자연어 처리#6 - 직방 부동산 평가데이터 전처리(1/2)
2020/03/28 - [AI/자연어처리] - [생활속의 IT] 자연어 처리#7 - 직방 부동산 평가데이터 전처리(2/2)
2020/03/31 - [AI/자연어처리] - [생활속의 IT] 자연어 처리#8 - Keras 모델 생성(1/3)
2020/04/02 - [AI/자연어처리] - [생활속의 IT] 자연어 처리#9 - Keras 모델 생성(2/3)
케라스로 딥러닝 모델을 만들기 위해 지금까지 모델을 만드는 과정에 대해 봤습니다.
모델을 만드는 유형에는 Sequential 방식과 Funtional 방식이 있다고 하였으며
비용함수를 이용하여 오버피팅을 방지하기 위한 조기종료가 가능하고
비용함수가 최저점이 되는 방향으로 역전파 알고리즘을 수행한다고 하였습니다.
그런데 딥러닝 모델을 만들기 위한 세부적인 작업이 조금 더 필요합니다.
이 부분도 커맨드 자체는 몇 줄 되지는 않습니다만, 꽤 많은 배경지식을 필요로 하기 때문에
본 포스트에서도 배경 지식 설명 위주로 작성하도록 하겠습니다.
1. Keras의 조기 종료조건(Early Stopping)
2. Karas의 Checkpoint 이해
3. Keras의 모델 컴파일 이해
4. Keras의 모델 Fit 이해
----------------------------------------------------------------------------------------------------------
1. 조기 종료조건의 이해
이전 포스트 (2020/03/31 - [AI/자연어처리] - [생활속의 IT] 자연어 처리#8 - Keras 모델 생성(1/2) 에서
조기 종료의 필요성에 대해 설명했습니다.
복습하자면, Training 데이터로만 학습시키면 정확도는 증가하지만 데이터간의 분산성이 높아져
오버피팅이 발생하기 때문에 적절한 시점에 종료시켜야 한다는 겁니다. (아래 참고)

Keras에서는 조기종료를 위한 코드를 제공하고 있습니다.
백문이 불여일견, 코드부터 보도록 하겠습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
|
model = Sequential()
model.add(LSTM(128))
es = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=4)
|
조기 종료를 위한 함수인 EarlyStopping은 tensorflow.keras.callbacks 패키지에서 제공하고 있습니다.
(callback 패키지는 많은 함수를 제공하고 있고 Early Stopping은 그 중 하나입니다)
따라서 오버피팅 방지를 위한 조기 종료 코드 작성은 단순히 es 로 시작하는 한 줄로 작성이 가능합니다.
다만 의미를 알아야겠죠?
monitor
- monitor는 무엇을 조기 종료의 조건으로 삼을 것이냐를 묻는 파라미터입니다.
주로 val_loss와 val_acc가 쓰이는데 보통 val_loss를 쓰며 이는 검증데이터의 비용함수 값을 모니터링하게 됩니다.
mode
- mode는 {min, max, auto} 중 하나로 넣을 수 있습니다.
mode='min'이면 monitor 하는 대상이 최소값이면 training을 종료해라 라는 뜻입니다.
반면 mode='max'이면 monitor 하는 대상이 최대값이면 종료하라는 뜻입니다.
mode='auto'이면 monitor 대상에 따라 keras가 알아서 판단하게 됩니다.
다시 위 코드를 해석해보면 monitor = 'val_loss' 는 검증 데이터셋의 비용함수를 모니터링하며
mode='min'에 의해 검증 데이터셋의 비용함수가 최저가 되는 부분에서 training을 멈춰라가 됩니다.
verbose
- 0 or 1 or 2의 값을 가질 수 있으며
얼마나 자세하게 로 지정할 경우 언제 조기종료가 되었는지를 표시해주게 됩니다.
patience
- mode 파라미터에서 지정한 값으로 상태에 도달했을 때 바로 종료시키지 않고 몇 번 더 학습시킬 것인지 결정합니다.
monitor='val_loss' 이고 mode='min', patience=4이면 검증데이터셋의 비용함수가 최저점이 되어도
4번은 더 학습시켜라 라는 뜻이 됩니다.
min_delta
- 성능이 향상되었다 라고 판단할 수 있는 최소한의 변화량을 정하는 값입니다.
예를 들어 min_delta 값을 0.01로 한다면
비용함수 값이 0.005 -> 0.004 로 0.001 줄어든 것은 개선이 아닌셈이 됩니다.
일반적으로 0으로 놓기는 하지만 정답은 아닙니다. min_delta 값을 정하기 위해 소량의 데이터로 훈련 시켜보고
추이를 지켜보면서 min_delta 값을 정해주기도 합니다.
2. Karas의 Checkpoint 이해
조기종료의 조건을 정하면서 patience 값을 4로 주었습니다.
그래서 네 번의 학습을 더 시켰는데 끝난 결과를 보니 검증 데이터의 비용함수 값이 최저점을 지나왔다면?
다시 back 할수도없고.. 학습을 다시 시켜야할까요?
이런 경우를 위해 매번 학습 중간중간 모델을 저장해주는 기능을 제공하며
위에서 봤던 callback 패키지 중 checkpoint 메서드가 그 역할을 하고 있습니다.
"중간중간"의 조건과 횟수를 지정해주는 파라미터를 제공해주고 있는데 코드 먼저 보도록 하겠습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
|
model = Sequential()
model.add(LSTM(128))
es = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=4)
mc = ModelCheckpoint(filepath, monitor='val_loss', verbose=0, save_best_only=False, save_weights_only=False, mode='auto', period=1)
|
es 부분은 위에서 봤던 조기종료 메서드이고 그 아래의 mc 가 체크포인트를 지정해주는 메서드입니다.
파라미터는 Early stopping 메서드에서 봤던 파라미터와 비슷합니다.
filepath
- 중간중간 학습된 모델을 저장할 파일명을 지정하는 부분입니다.
monitor
- 조기종료와 마찬가지로 "무엇을" 보고 중간중간 저장할지를 지정하는 부분입니다.
주로 val_loss (비용함수 값)이나 val_acc (정확도)를 지정합니다.
verbose
- 0 or 1 or 2의 값을 가질 수 있으며 출력의 디테일 정도를 나타냅니다.
mode
- min, max, auto의 값을 가질 수 있으며 monitor 파라미터와 밀접한 연관을 가집니다.
monitor='val_loss' 일 경우 mode의 값은 min만 올 수 있으며
monitor='val_acc'일 경우 mode 값은 max만 올 수 있습니다.
mode='auto'는 keras가 monitor 파라미터를 보고 알아서 판단하도록 합니다.
save_best_only
- True 일 경우 monitor 대상이 최고값일 때만 저장하도록 합니다.
save_weights_only
- True일 경우 모델의 가중치 값만 저장하도록 하고
False 일 경우 모델 전체를 저장하도록 합니다.
Period
- 모델 저장 주기를 결정하는 것으로 값이 1인 경우 매 학습시마다 저장하게 됩니다.
3. Keras의 모델 컴파일 이해
위에서 설명한 조기종료(es)와 체크포인트(mc)는 mode.fit 단계에서 파라미터로 쓰이게 됩니다.
따라서 model.fit 을 수행하기 전에만 정의해주면 되는데 model.fit 하기 위해 한 단계가 더 필요합니다.
바로 모델 컴파일입니다.
Sequential이나 Functional 방식으로 정의한 Keras 딥러닝 모델을
컴퓨터가 이해할 수 있는 구조로 바꿈과 동시에 여러 파라미터를 지정할 수 있습니다.
코드 먼저 보겠습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
model = Sequential()
model.add(LSTM(128))
es = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=4)
mc = ModelCheckpoint(filepath, monitor='val_loss', verbose=0, save_best_only=False, save_weights_only=False, mode='auto', period=1)
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
|
es와 mc는 조기종료와 중간 저장을 위해 정의하는 callback 함수라고 위에서 설명했습니다.
model.fit을 수행하기 전 model.compile을 수행하게 됩니다.
optimizer
- 역전파 알고리즘을 선택하는 것으로 역전파 알고리즘에 대해서는 이전 포스트에서 설명하였습니다.
(2020/04/02 - [AI/자연어처리] - [생활속의 IT] 자연어 처리#9 - Keras 모델 생성(2/2)
[생활속의 IT] 자연어 처리#9 - Keras 모델 생성(2/2)
[이전 글 보기] 2020/03/22 - [AI/자연어처리] - [생활속의 IT] 자연어 처리#1 - 아나콘다 설치하기 2020/03/22 - [AI/자연어처리] - [생활속의 IT] 자연어 처리 - 참고) Jupyter의 개념 2020/03/23 - [AI/자연어..
itlamp.tistory.com
사용할 수 있는 옵티마이저로는 rmsprop, sgd, adagrad, adam 등이 있습니다.
loss
- 어떤 비용함수를 사용할지 정의하는 부분입니다. 이 부분 역시 이전 포스트에서 설명하였습니다.
주로 많이 쓰는 비용함수는 실제값과 예측값의 오차 제곱합을 의미하는 MSE(Mean Square Error)이며
분류에서는 cross entropy를 사용한다고 하였습니다.
다중 분류시에는 categorical cross entropy를 쓰지만 이진분류에서는 binary cross entropy를 주로 사용합니다.
metrics
- 훈련, Test 셋 적용시 모델 평가를 위한 metric을 정의하는데 일반적으로는 accuracy를 사용합니다. (acc)
모델의 output이 여러개인 복잡한 모델인 경우 output마다 metric을 다르게 적용할 수 있습니다.
여기까지 이해하였으면 마지막으로 남은 것은 모델 훈련이 시작되는 model.fit 부분입니다.
4. Keras의 모델 Fit 이해
model.fit 부분에서 학습이 시작되는데 파라미터를 설명함에 앞서
에포크(epochs)와 배치 크기를 이해할 필요가 있습니다.
딥러닝의 학습과정은 문제집을 푸는 과정으로 비유할 수 있는데 그림을 보면서 이해해 보겠습니다.
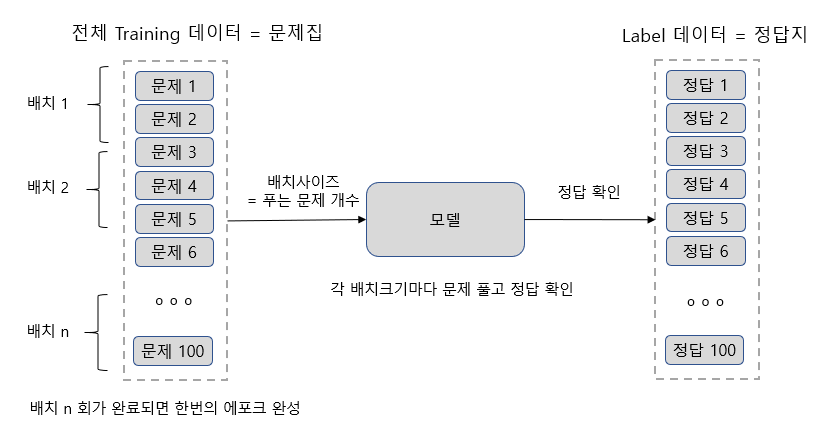
- batch_size는 한번에 몇 개의 문제를 풀 것인지를 지정하는 것으로
batch_size 만큼이 완료될 때마다 가중치를 조정하는 작업이 일어나게 됩니다.
예를 들어 batch_size가 10이면 10개의 문제를 풀고 정답을 확인한 후 지식을 수정하는 것이죠.
- training 데이터셋이 1000개이고 batch_size가 10이라면 100번의 지식 수정 작업이 일어나게 됩니다.
모델에서는 가중치를 수정하는 작업이 100번 일어난다는 의미가 됩니다.
이렇게 100번의 과정이 완료되면 하나의 epochs (에포크)가 완료되었다고 합니다.
- 다음 에포크에서도 동일한 training 데이터로 훈련을 반복합니다.
사람도 책을 처음 읽을 때와 두 번째 읽을 때 책 속의 내용을 깨닫는 정도가 달라지는데,
딥러닝도 유사한 과정을 거친다고 보면 되겠습니다.
두 번째 에포크때 가중치가 좀 더 목표치에 가까워지게 됩니다.
- Keras의 model.fit에서는 에포크를 몇 번 할 것인지를 지정하는데 보통 10~20 사이의 값을 넣어줍니다.
이제 코드를 한번 보겠습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
model = Sequential()
model.add(LSTM(128))
es = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=4)
mc = ModelCheckpoint(filepath, monitor='val_loss', verbose=0, save_best_only=False, save_weights_only=False, mode='auto', period=1)
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
history = model.fit(X_train, Y_train, epochs=15, callbacks=[es, mc], batch_size=60, validation_split=0.2)
|
model.fit은 맨 아래에 있습니다.
epochs
- 에포크를 15회로 지정하였습니다. 즉 전체 데이터셋에 대해 15번 학습을 반복한다는 의미입니다.
callbacks
- callbacks에서 es와 mc를 지정하였는데 이것은 앞에서 설명한 조기종료와 체크포인트 설정 값을 의미합니다.
batch_size
- 배치사이즈는 60인데 이것은 곧 60개의 데이터를 모델에 통과시켜 얻은 비용함수를 가지고
가중치 조정하는 작업을 하겠다는 의미입니다.
만약 배치사이즈가 100,000 건이고 배치사이즈가 60이라면 100,000 / 60 = 1666.66 이므로
한번의 에포크마다 1667회의 가중치 조정작업이 일어난다고 볼 수 있습니다.
validation_split
- 입력한 training 데이터에서 검증용으로 얼마나 사용할지 비율을 정해줍니다.
여러 번 설명하였지만 오버피팅 방지를 위해 검증 데이터는 반드시 필요합니다.
참고로 test셋과 검증셋은 다릅니다.
test셋은 모델이 완성된 후 정확도가 얼마나 나오는지 알아보기 위한 세트입니다.
반면 검증 데이터는 모델을 만드는 도중에 사용되며
훈련이 진행됨에 따라 검증 데이터셋의 비용함수 값이 v 모양으로 그리게 되므로
이를 기반으로 조기종료할 수 있도록 이용되는 세트입니다.
'AI > 자연어처리' 카테고리의 다른 글
| [생활속의 IT] 자연어 처리#9 - Keras 모델 생성(2/3) (0) | 2020.04.02 |
|---|---|
| [생활속의 IT] 자연어 처리#8 - Keras 모델 생성(1/3) (0) | 2020.03.31 |
| [생활속의 IT] 자연어 처리#7 - 직방 부동산 평가데이터 전처리(2/2) (3) | 2020.03.28 |
| [생활속의 IT] 자연어 처리#6 - 직방 부동산 평가데이터 전처리(1/2) (0) | 2020.03.26 |
| [생활속의 IT] 자연어 처리#5 - 직방 부동산 평가 크롤링하기 (1) | 2020.03.24 |




댓글