[이전 글 보기]
2020/03/22 - [AI/자연어처리] - [생활속의 IT] 자연어 처리#1 - 아나콘다 설치하기
2020/03/22 - [AI/자연어처리] - [생활속의 IT] 자연어 처리 - 참고) Jupyter의 개념
2020/03/23 - [AI/자연어처리] - [생활속의 IT] 자연어 처리#2 - 크롤러 만들기
2020/03/23 - [AI/자연어처리] - [생활속의 IT] 자연어 처리#3 - 직방의 지리정보 Geohash 이해하기
2020/03/24 - [AI/자연어처리] - [생활속의 IT] 자연어 처리#4 - 직방 아파트ID 얻기
2020/03/24 - [AI/자연어처리] - [생활속의 IT] 자연어 처리#5 - 직방 부동산 평가 크롤링하기
2020/03/26 - [AI/자연어처리] - [생활속의 IT] 자연어 처리#6 - 직방 부동산 평가데이터 전처리(1/2)
2020/03/28 - [AI/자연어처리] - [생활속의 IT] 자연어 처리#7 - 직방 부동산 평가데이터 전처리(2/2)
전처리 코드는 모두 작성했습니다.
이제 학습만 시키면 되는데 사실 학습은 코드가 몇 줄 되지 않습니다.
대신 그 안에 담고 있는 의미를 파악하려면 기본적인 지식이 필요합니다.
모델의 생성과정을 설명하는데 있어 그 의미를 파악하는데 주력하여 포스트를 작성하고자 합니다.
1. Keras의 모델 생성 원리
2. Layer의 유형
--------------------------------------------------------------------------------------------------------------------
1. Keras의 모델 생성 원리
Keras을 이용하여 딥러닝 모델을 구현할 수 있는데 구현할 수 있는 방식이 크게 두 가지로 구분됩니다.
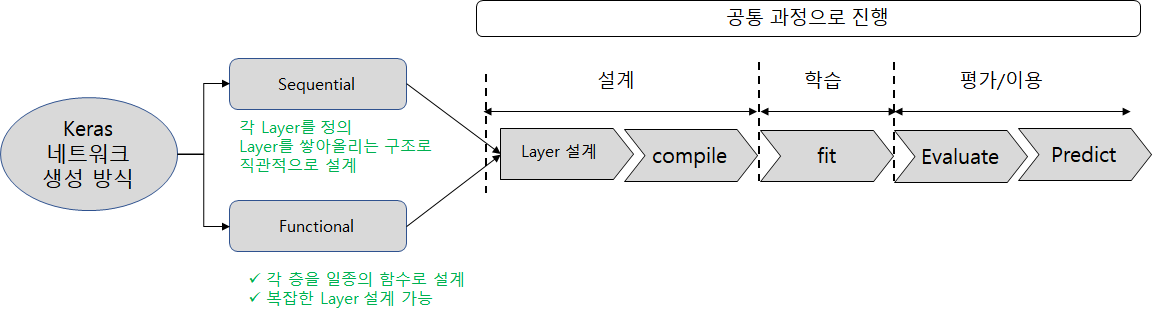
하나는 Sequential 방식으로 구현하는 것이고 하나는 Functional 방식으로 구현하는 것입니다.
참고로 모델을 설계하는 방식만 다른 것이고, 컴파일(Compile)하여 컴퓨터에게 인식시키고, 학습(Fit) 시키고 평가(Evaluate) 후 이용(Predict)하는 단계는 모두 동일합니다.
이제 이 두 방식이 어떻게 다른지 설명하도록 하겠습니다.
(1) Sequantial 방식
Sequantial 방식은 아래처럼 각 층을 정의한 후 하나씩 적층해주는 것입니다.

대부분의 딥러닝 구조는 이 구조로 해결이 됩니다.
만들기 간편하고 꽤나 직관적이라 복잡한 딥러닝 구조를 설계할 필요가 없다면 대부분 sequantial로 만들게 됩니다.
그런데 좀 더 실험적인 모델 설계가 필요한 전문가들에겐 다소 자유도가 떨어지는 것이 단점입니다.
이를 해결하기 위한 설계 방식이 Functional 방식입니다.
정확히 어떤 경우에 Fuctional을 쓰면 좋을까요?
(2) Functional 방식
백문이 불여일견이라고 Keras Document에 있는 Functional 설계 방식을 내용을 그림으로 그려보았습니다.

functional 설계 방식이 이해가 되시나요?
즉 (1) 다수 입력/다수 출력을 가진 모델이나 (2) 모델을 공유하는 경우나 (3) 모델을 병합하는 경우등
여러 케이스에 걸쳐 좀 더 유연하게 모델을 만드는 방식이라고 보면 됩니다.
그리고 Functional 설계 방식의 경우 함수 방식으로 설계하게 됩니다.
즉 아래 층을 입력 pamaneter로 받아들여 함수를 정의하듯 설계할 수 있어 좀 더 다양한 모델을 만들 수 있는 것입니다.
모델 구조 자체를 정의하는 것은 Sequantial 과 Fuctional 방식이 이렇게 다르지만
모델에 들어가는 Layer 자체는 동일한 유형을 사용할 수 있습니다.
어떤 Layer를 사용할 수 있는지 보도록 하겠습니다.
2. Layer의 유형
Sequantial 은 각 층을 정의한 후 이어붙이는 방식이라고 했습니다.
각 층을 정의할 때는 다양한 Layer를 이용할 수 있습니다.
어떤 Layer를 쓸 수 있는지 한번 보도록 하겠습니다. 코드는 Sequential 방식의 코드를 넣었습니다.
(1) Fully Connected Layer (=Dense Layer)
단순히 이전 층과 Fully 연결된 층을 정의합니다.
제일 단순한 Layer이지만 이 구조가 인간의 뇌에 있는 뉴런과 시냅스 모양을 가장 잘 따라한 모양이기도 합니다.

위와 같은 2개의 층을 가진 Dense Layer를 위해 코드는 아래처럼 작성합니다.
|
1
2
3
4
5
6
7
|
model = Sequential()
|
2개의 층을 만들기 위해 .add(Dense()) 함수를 2번 연달아 썼습니다.
첫 Layer를 정의할 때만 input 개수를 정의하며 그 이후의 Dense Layer는 자동적으로 이전 출력을
입력으로 받게 되기 때문에 별도로 input_dim을 정의하지 않습니다.
Dense함수의 인수는 아래와 같습니다.
○ 첫 번째: 출력 노드 개수
○ input_dim: 입력 차원 수
--> 만약 학습할 문장이 50 차원 (50개의 토큰)으로 구성되어 있다면 input_dim은 50이 됩니다.
○ activation: 다음 노드로 값을 전달할 크기를 정하기 위한 함수입니다.
--> Relu는 Sigmoid를 개선하여 기울기 소실을 해결한건데 본 포스트에선 자세히 설명하진 않겠습니다.
그 외에도 많은 인수들이 있는데 궁금하신 분은 Keras Document를 참고해보세요.
(2) Embedding Layer
Word2Vec을 위해 첫 번째 Layer에만 쓸 수 있는 Layer 입니다.
Word2Vec이 무엇이냐면 인간이 이해하는 단어를 숫자로 된 Vector로 변환한다는 것을 의미합니다.
전처리 과정을 설명할 때 각 단어의 등장 횟수 순위별로 매핑한다고 했는데 이 과정과는 별개입니다.
Embedding Layer가 입력받는 값과 출력하는 값을 보면 이해가 갈 것입니다.
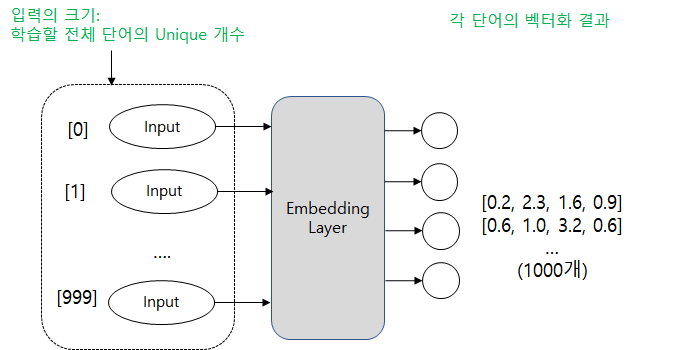
먼저 Embedding Layer가 입력받는 input의 크기는 학습할 전체 단어의 개수가 됩니다.
고빈도 단어의 개수가 1000개 라면 1000이 Embedding Layer의 입력 크기가 됩니다.
○ 크기는 그렇고, 그러면 입력 값은 뭘까요?
우리가 학습시킬 문장이 들어가게 됩니다. 토큰화로 Split 되고 정수로 인코딩한 문장이 들어가는 것이죠.
○ 출력으로는 뭐가 나올까요?
위 그림은 출력 개수를 4개로 그렸는데 정확히는 벡터화 시킬 크기 만큼 출력되게 됩니다.
만약 모든 단어를 4차원으로 벡터화시키고 싶다면 위 처럼 4개의 출력값이 생기겠죠.
그래서 출력되는 값은 각 단어의 벡터화된 결과가 나오게 됩니다.
즉 Embedding Layer는 각 단어를 특정 N 차원으로 벡터화하여 출력하게 됩니다.
그런데 여기서 중요한 것은 유사한 단어, 혹은 쓰임상 자주 연결되는 단어는 유사한 값으로 벡터화된다는 것입니다.
예를 들어 과일과 딸기는 유사한 의미를 가지므로 비슷한 값으로 벡터화되게 됩니다.
(수학적으로는 유클리디안 거리나 맨하탄 거리 등을 계산해 거리가 가깝다라고 합니다)
그럼 코드를 보겠습니다.
|
1
2
3
4
5
6
7
8
|
model = Sequential()
|
Embedding Layer의 인수는 아래와 같습니다.
○ 첫 번째: input 차원 크기, 학습할 전체 단어 개수라고 설명했습니다.
--> 전처리 결과에 따라 고빈도 단어를 vocabSize로 정의했으므로(이전 포스트 참조) 이 변수를 전달
○ 두 번째: 각 단어가 벡터화 결과로 나올 차원 크기, 위에선 100차원으로 학습하겠다는 의미
그 외 몇 가지 변수가 더 있는데 보통 이 두 가지 변수면 학습이 가능합니다.
(3) LSTM (Long Term Short Memory) Layer
RNN의 기울기 소멸 문제점으로 인해 오래 전 단어를 제대로 기억하지 못하는 단점을 해결하기 위해
LSTM이 등장했습니다.
RNN과 LSTM을 설명하기에는 양이 많아 다른 사이트를 참조해서 이해하시길 권고드립니다.
간단히 말하자면 LSTM은 input, forget, output 3개의 스위치를 통해 기억을 조절하며
이를 통해 RNN의 단점을 개선한다고 보면 됩니다.
아래 그림은 RNN그림인데 LSTM은 저 초록색 네모의 각 화살표마다 스위치가 달려있다고 보면
비슷합니다.
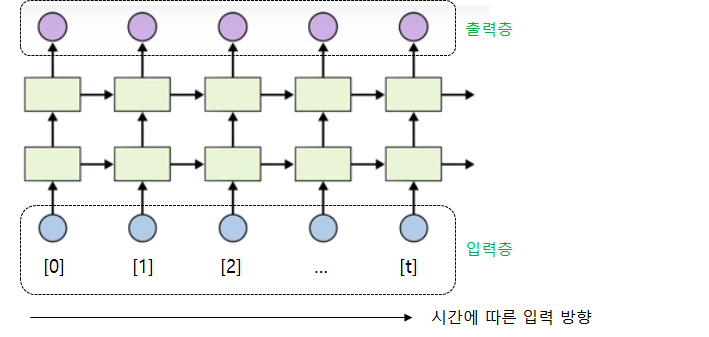
어쨌든 LSTM은 이전 입력값의 학습 결과가 다음 학습에 영향을 주는 시간의 개념을 가지고 있습니다.
그래서 시계열 데이터 분석에 자주 사용되며 언어 또한 시계열적인 특성을 담고 있기에
자연어 처리에도 적합한 모델입니다. 그래서 우리가 사용할 Layer에 LSTM도 있습니다.
코드는 아래와 같이 작성합니다.
|
1
2
3
4
5
6
7
8
|
model = Sequential()
|
첫 번째 인수는 출력의 차원 크기
두 번째 인수에서 앞(3)은 예측에 사용할 시간 구간, 뒤(5)는 데이터셋의 컬럼 크기를 의미합니다.
LSTM 또한 무수히 많은 인수를 넣을 수 있으므로 Keras Document를 참고해보면 되겠습니다.
LSTM을 첫 번째 Layer로 정의할 수 있지만 두 번째 이상부터도 사용할 수 있으며
이 경우 Dense Layer와 마찬가지로 input_shape는 정의하지 않아도 됩니다.
일단 Layer 소개는 여기까지 하겠습니다.
이미지 처리에 많이 쓰이는 컨볼루션 Layer나 Pooling 레이어 등 아직 소개하지 못한 Layer가 7가지 정도 되는듯 합니다.
사실 우리가 수행할 자연어 처리에 필요한 레이어는 지금까지 소개한 Embedding, LSTM, Dense 3개 입니다.
다음 포스트에서 모델 설계를 해보면서 추가 상세 설명을 붙이도록 하겠습니다.
'AI > 자연어처리' 카테고리의 다른 글
| [생활속의 IT] 자연어 처리#10 - Keras 모델 생성(3/3) (0) | 2020.04.15 |
|---|---|
| [생활속의 IT] 자연어 처리#9 - Keras 모델 생성(2/3) (0) | 2020.04.02 |
| [생활속의 IT] 자연어 처리#7 - 직방 부동산 평가데이터 전처리(2/2) (3) | 2020.03.28 |
| [생활속의 IT] 자연어 처리#6 - 직방 부동산 평가데이터 전처리(1/2) (0) | 2020.03.26 |
| [생활속의 IT] 자연어 처리#5 - 직방 부동산 평가 크롤링하기 (1) | 2020.03.24 |




댓글